
CONFERENCE REPORT: WRITING VOICE AND SPEAKING TEXT: AN INTERDISCIPLINARY ENQUIRY INTO DIACHRONIC AND SYNCHRONIC ASPECTS OF SPEECH
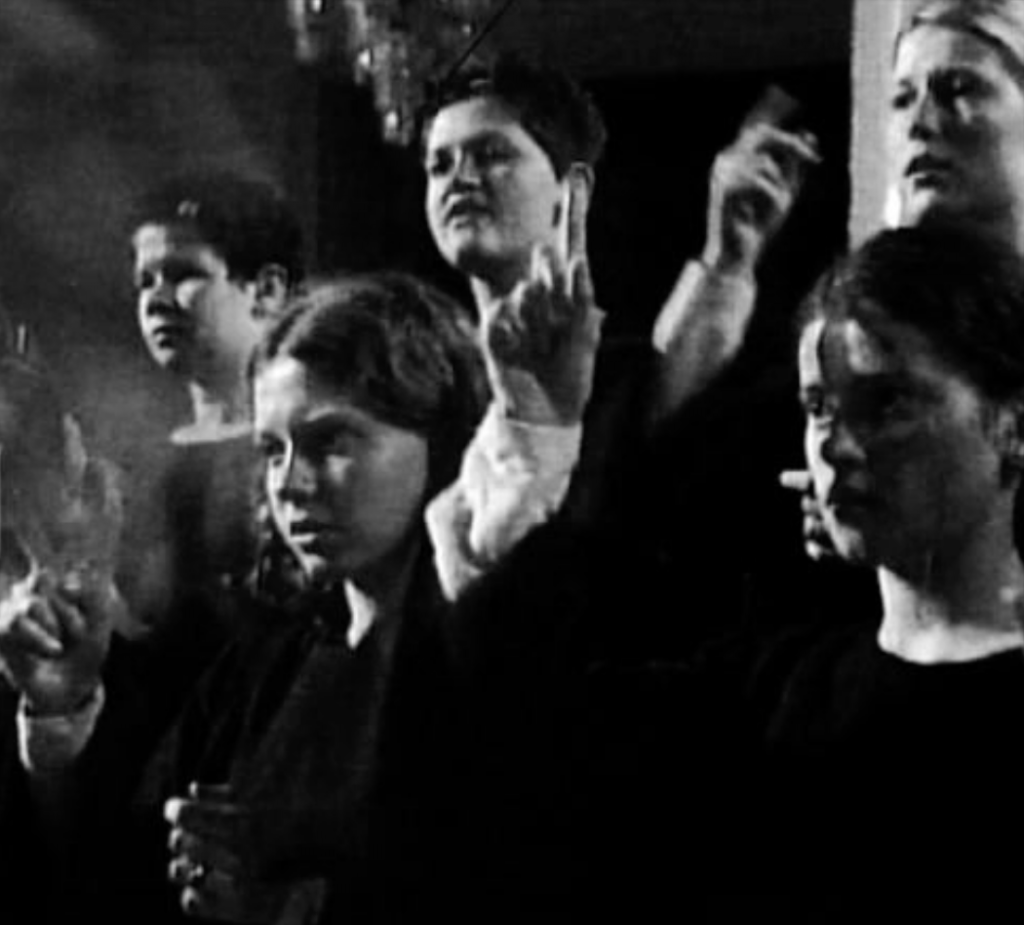

Dr Josephine Hoegaerts is an associate professor for European studies in the Department of Cultures at the University of Helsinki.
“Writing is always a kind of imitation talking,
and in a diary I therefore am pretending that I am talking to myself.”
Walter Ong, Orality and Literacy (1982)
On 6-8 June 2018, the symposium “WRITING VOICE AND SPEAKING TEXT An Interdisciplinary Enquiry into Diachronic and Synchronic Aspects of Speech” took place at the Helsinki Collegium for Advanced studies. Gathering scholars from disciplines across the humanities (including linguists, anthropologists, historians and sociologists), the symposium focused on the particular relationship researchers in the humanities have with “words” written and spoken, and on the links and tensions between the written and spoken word. Walter Ong’s views on orality and literacy, expressing what can perhaps be seen as a now “mainstream” understanding of the relationship between speech and text, served as a point of departure for the symposium’s theme, but also as a starting point for thinking more critically about the assumed connections between speech and writing. And also as an incitement to think about both in a more material fashion, including audibility and tangibility in our understanding of “words”. Rather than trying to tease out whether text and speech relate to each other much like an “original” and a “copy” would (in either direction, as text can “transcribe” as well as “prescribe” speech), the symposium revealed a wide array of perspectives on what is considered a “voice” in different disciplines. Most strikingly, perhaps, doing so has led to interpretations that place the (audible/human/authorial) voice in a much more broadly defined soundscape. In thinking through the relationship between the spoken and the written word, many contributors also drew on the exchanges between human, animal and machine sounds – and indeed insisted on the centrality of “sound” in understanding language regardless of media.
In its original inception, the symposium wanted to address the links and tensions between spoken and written language exactly in those instances where they seem (or pretend) to mirror each other quite precisely. In speech-to-text interpreting, for example, in the prescriptive nature of a poem to be read aloud, or in the practice of transcribing interviews in order to analyse their spoken message. Though sensitive to different modes of narrative and orality, analyses of these types of “transcription” have often rested on the implicit assumption that speech and text are, if not identical, at least closely related. As if writing is indeed “imitation talking”, a copy – albeit a poor one – of spoken reality (Chittick 1988, Galembert et al. 2014). Recent studies in literature, linguistics and sound studies – including work by contributors to the symposium – have questioned this “phonographic claim” (Butler 2015), and have reframed the relation between written and spoken language as one of shared “matter” or roots rather than mimesis – and as the result of extensive cultural and technological work (Bergeron 2010; Connor 2004). And indeed, the main finding of the symposium may very well be that an understanding of language as a “shared” reality is crucial if we want to be able to work with “words” in a meaningful way. In some way or other, all contributions underlined that no “voice” can be seen as a free-standing sound or performance. Whether it be in the inter-subjective experience of an interview, analysing prosody in audio-books, re-imagining Shakespearian jokes or contextualizing Deaf voices: speech and voice never occur in a vacuum, and therefore cannot be studied in isolation. Despite a wide array of different scholarly backgrounds, approaches, methodologies and datasets discussed at the symposium, the notion of sounding contexts of both speech and text (and thus of soundscapes of different kinds) resurfaced throughout.
The analysis of these contexts proved necessary for several reasons, but the most important was perhaps that our experiences and practices of speech always depend on extensive (and often very technological) mediation. Even if the focus of most contributions was squarely on human voices and imaginations, the embodiment of the spoken and written word appeared to pierce the limits of “humanness” often and easily. This was the case, for example, in Liisa Tiitula’s paper on “Speech-to-text transfer for deaf and hard-of-hearing people”. Tiitula gave an overview of the different practices used to give access to speech in a visual/written form: a type of simultaneous interpreting resulting in a dynamic text that appears on screen in chunks and (like spoken language) disappears as the speaker goes on talking. Her paper showed how deeply intertwined the interpreter’s practice and the technology used to produce transcriptions are and how this results in different perspectives on the role and identity of the interpreter using these technologies. Whereas consumers seem to favour a machine-like verbatim rendition of speech (a “transcription”), the producers think of their task as one of interpretation, necessitating a host of conscious choices to make the written record match the tone and feel as well as the content of the spoken word as closely as possible. Similar processes of constant decision-making were at issue in the paper by Maija Hirvonen and Mari Wiklund on “The effects of speech prosody on information sequencing in audio-description”. The analyses of the prosodic cues used in the audio-descriptions (narrative descriptions of visual information, such as a painting for example, to make them accessible to people without vision) were carried out using specialized software. They aimed at understanding how human ears can distinguish between the end of sentence or a paragraph (mimicking punctuation) but also between sounds describing the foreground and those rendering the background of a painting. (The latter being pitched lower than the former.) Despite a clear focus on voice and sound, Hirvonen’s and Wiklund’s contribution also drew attention to what became another central issue of the conference: the need to think about the senses from synesthetic perspective. Audio-descriptions rely on aural complexity to echo visual complexity and make it accessible to those without vision – thus underlining the need to think of the ”senses” as connected rather than distinct entities. Panos Panopoulos stressed this connected nature of the senses in other ways in his presentation on “Deaf Voices: Vocality Through and Beyond Sound and Sign”. The world of the Deaf, as Panopoulos pointed out, is not soundless, just not dominated by hearing. Engaging with the Deaf voice and Deaf art therefore necessitates an exercise in reframing sound studies for it to meet Deaf studies and focus on, for example, the haptic elements of sound. In order to question hearing people’s ownership of sound and re-frame it as “touch” Deaf artists such as Christine Sun Kim present artistic work in which one is immersed in the materiality of the voice and Panopoulos’ paper represented a careful anthropological engagement with the meanings created in such work.
Audio: A fragment of Singing lesson (2001), Artur Zmijewski’s work about deaf children learning to sing a fragment from the Polish Mass by Jan Maklakiewicz (1899–1954). Youtube.
As the stark distinction between the dominance of the hearing world and artistic endeavours to make sound haptic already show, power and the social dimension of speech and spoken performances played an important role in discussions throughout the symposium. Speech is, of course, always already social, as it cannot stand on its own. In different media, the spoken word is always a matter of collaborative construction, between those who engage in dialogue, between a speaker and an audience, but also between the speaker and the language she uses or the cultural world in which her words are launched (even if no audience is present at the time of speaking). This was obvious in Ilya Sverdlov’s presentation on parsing strategies in Old Norse skaldic poetry, which showed how active membership in a language community (and close acquaintance with its oral characteristics) impacts one’s ability and intuitions to disentangle complex Norse “kennings”. Oral and aural skills are built intersubjectively, and interact with more abstract linguistic skills which often dominate the discourse on epic poetry. Constructions of speech and language in dialogue show this need for intersubjective understandings of “voice” even more starkly. Karita Suomalainen’s presentation on “Creating shared perspectives with the second person singular” convincingly showed how particular linguistic constructions can be used to create a community of emotion or opinion by essentially extracting an agreement from one’s partner in dialogue by the use of the “generic you” (expressed in different ways in Finnish). Likewise, Hanna Lappalainen’s analysis of “quotatives” (voicing others’ speech in one’s own discourse) focused on a number of linguistic strategies in which speech is shared. Taking different ways of “reporting” speech in one’s own spoken language into account, Lappalainen showed that female speakers have a greater tendency to use quotatives than male speakers, but also that older speakers are more likely to do so than youngsters (despite a general feeling that quotatives along the lines of “and he was like …” are on the rise). The intersubjective quality of dialogue is therefore even greater than we may think: not only the voice of two speakers is exchanged, other “voices” make regular appearances in conversations as well, and help to construct the soundscape of the exchange.
Although Lappalainen’s and Karita’s analyses are based on largely unstructured, intuitive exchanges, it is clear that approaches to dialogue and speech like theirs can be brought to bear on other types of research that rely on speech for its primary data. Two contributions reflecting on the use of interviews for social and anthropological research drew attention to the importance of vocal and verbal inflection for the interpretation of these very specific types of dialogue. Matti Hyvärinen and Hanna Rautajoki, for example, explored Bamberg’s notion of “positioning” in conversation, drawing on both transcriptions and recordings of an interview with three active participants. Their analysis showed that aural aspects of the interview – which are largely lost in transcription – can have a significant impact on interpretation. Prosodic markers, for example, played an important role for participants to position themselves in the conversation and to play with performances of agreement and discord through the use of prosodically marked quotatives such as those analysed by Lappalainen in her paper. Molly Andrew’s contribution, which likewise focused on interviews and particularly on her own interviewing practice, also stressed the aural landscape of the interview. “Hearing, representing and performing the pain of others” all depend, according to Andrews, on a willingness to engage in the intersubjective practice of speech in an interview – even if that practice results in prolonged silences. As she grappled with the gap between teller and listener, and the tensions it can create for ethical scholarship, Andrews also problematized the notion of writing as “empowering”, or the equation of writing voices were language fails with a redemptive or emancipatory act, thus drawing attention to practices of speech and silence rather than analysis and transcription. The teller’s voice, however fragile, can therefore serve as a thread to allow the scholar to “follow the teller into a world of radical otherness”.
Practices of writing “others’” voices are central in the work of many social scientists and humanists, and the source of multiple tensions in scholarship. Andrew’s paper was by no means the only one to address the somewhat ambiguous issue of “ventriloquism”: practices of voicing the words of one’s research subjects or interlocutors, or instances of (historical) actors “throwing” their voice across the divide between scholarly analysis and the “real world”. Ann Wichman, who opened the symposium, addressed the issue of ventriloquism in her talk on “Reading aloud”, showing how readers of e.g. audiobooks or news reports serve as mouthpieces for particular emotional repertoires. Prosody (pitch variation in speech) can therefore be read as a cultural practice performed at the interface between authorial decisions, the reader’s physicality and culturally shared notions of how emotions can be “heard” in speech. Venturing outside one’s cultural soundscape can therefore lead to alienation and misunderstanding beyond language: the prosodic landscape available to convey emotion differs across time and place. As Lotta Aarikka’s paper on the history of research on dialects in Finland showed, one need not cross national borders to encounter different cultural landscapes. Aarikka’s study of dialect researchers and her central question (“whose voice can be heard in dialect data?”) showed that different intellectual ambitions or research schools account for as much variety as regional or historical differences. Moreover, she too reflected on the entangled issues of transcription and ventriloquism and their central role in thinking through the ethics and politics of research. She critically examined the images and self-images of linguists engaging in dialect research, the “gathering” of data, and the representation of the “othered” voices of dialect speakers across Finland. The “othered” and ventriloquized voices in Shane Butler’s paper not only crossed space and time, but species as well. Focusing on the rendering of “animal” voices in poetry, Butler examined how writing facilitates the “migration of words” but also struggles to represent language, particularly when it is non-textual. Drawing on the classic distinction between vox confusa and vox articulata, Butler’s analysis of Philomela’s complaint raised questions both about the “human” nature of the soundscape of speech and about the politics of transcription.
That transcription and the migration of language between voice, speech and text are never innocent or a-political is clear, but crystallized connections between speech, text and power were perhaps most obvious in three contributions dealing with more obviously historically-narrative issues. Laura Ekberg’s study of Caribbean fiction and its heterolingualist use of English, for example, showed how the rendering of different voices and the issue of whose voice is rendered (especially in a “foreign” soundscape) reflects relations of Otherness and power. The contributions by Anu Korhonen and Josephine Hoegaerts, respectively on representations of “fools” on the early modern stage and the presence of speech impediments in modern representative politics, both showed how the historical “record” presents a politically charged soundscape in its own right, in which some voices reverberate in more obvious ways than others. Dealing both with rather hegemonic spaces (the stage and parliament), both papers drew on elaborate transcriptions that had been designed to showcase some voices and silence “others”. In both cases, the recognition of these contexts as soundscapes allowed for a rereading of these incomplete “transcriptions” in order to at least relocate some of the more unconventional voices of the past. Although these contributions – unlike the ones using linguistic and interview data – were based on an entirely “silent” set of sources usually seen as mere text rather than a refraction of speech, it became clear that in literature and historical text, too, it pays to attend to the voice. To not read against the grain, but listen with and against transcription and along the lines of words’ migration across media.
References
Bergeron, Katherine 2010. Voice Lessons. French mélodie in the Belle Epoque. Oxford: Oxford University Press.
Butler, Shane 2015. The Ancient Phonograph. Cambridge, MA: Zone Books.
Chittick, Kathryn 1988. “Dickens and Parliamentary Reporting in the 1830’s”, Victorian Periodicals Review 21 (4): 151–160.
Connor, Steven 2004. Dumbstruck. A Cultural History of Ventriloquism. Oxford: Oxford University Press.
Galembert et al. 2014. Faire parler le Parlement. Méthodes et enjeux de l’analyse des débats parlementaires pour les sciences sociales, Paris: LGDJ.
Ong, Walter J. 1982. Orality and Literacy. The Technologizing of the Word. London & New York: Routledge.
Conference programme
Organizers: Mari Wiklund, Josephine Hoegaerts, Ann Phoenix and Ilya Sverdlov
Session 1: Transcribed voices
Chair: Mats Bergman
Anne Wichmann (University of Central Lancashire): Reading aloud: prosodic cues to participant roles
Maija Hirvonen & Mari Wiklund (University of Helsinki & HCAS): What a difference the voice makes… The effects of speech prosody on information sequencing in audio description
Hanna Lappalainen (University of Helsinki): Quotatives as means of combining different voices
Session 2: Voice and text in conversation
Chair: Jonna Katto
Molly Andrews (University of East London): Hearing, representing and performing the pain of others: Tensions of ethical scholarship
Matti Hyvärinen & Hanna Rautajoki (University of Tampere): Positioning with text and voice – a case study
Session 3: “Other” voices in history
Chair: Elise Garritzen
Shane Butler (John Hopkins University): Philomela’s Complaint
Anu Korhonen (University of Helsinki): Giving Voice to Fools. Speech Disorders in Early Modern Drama
Josephine Hoegaerts (University of Helsinki): Echoes of unconventional and pathological speech in nineteenth century parliamentary reports
Session 4: Deaf voices and Speech-to-Text
Chair: Alexandre Nikolaev
Panayotis Panopoulos (University of the Aegean): Deaf Voices: Vocality Through and Beyond Sound and Sign
Liisa Tiittula (University of Helsinki): Speech-to-text transfer for deaf and hard-of-hearing people
Session 5: Epic Voices
Chair: Eila Stepanova
Ilya Sverdlov (HCAS): Oral, post-oral, aural, written – different media, same parsing strategies in Old Norse skaldic poetry
Session 6: Whose voice? – Langnet PhD student session
Chair: Simo Määttä
Lotta Aarikka: Whose voice can be heard in dialect data?
Laura Ekberg: Translating spoken language in Anglophone Caribbean fiction
Karita Suomalainen: Whose voice, whose experience? Creating shared perspectives with second person singular
***
Cover photo: Screen capture from ‘Singing lesson’ (2001) by Artur Zmijewski.